Transcloud
April 24, 2026
April 24, 2026
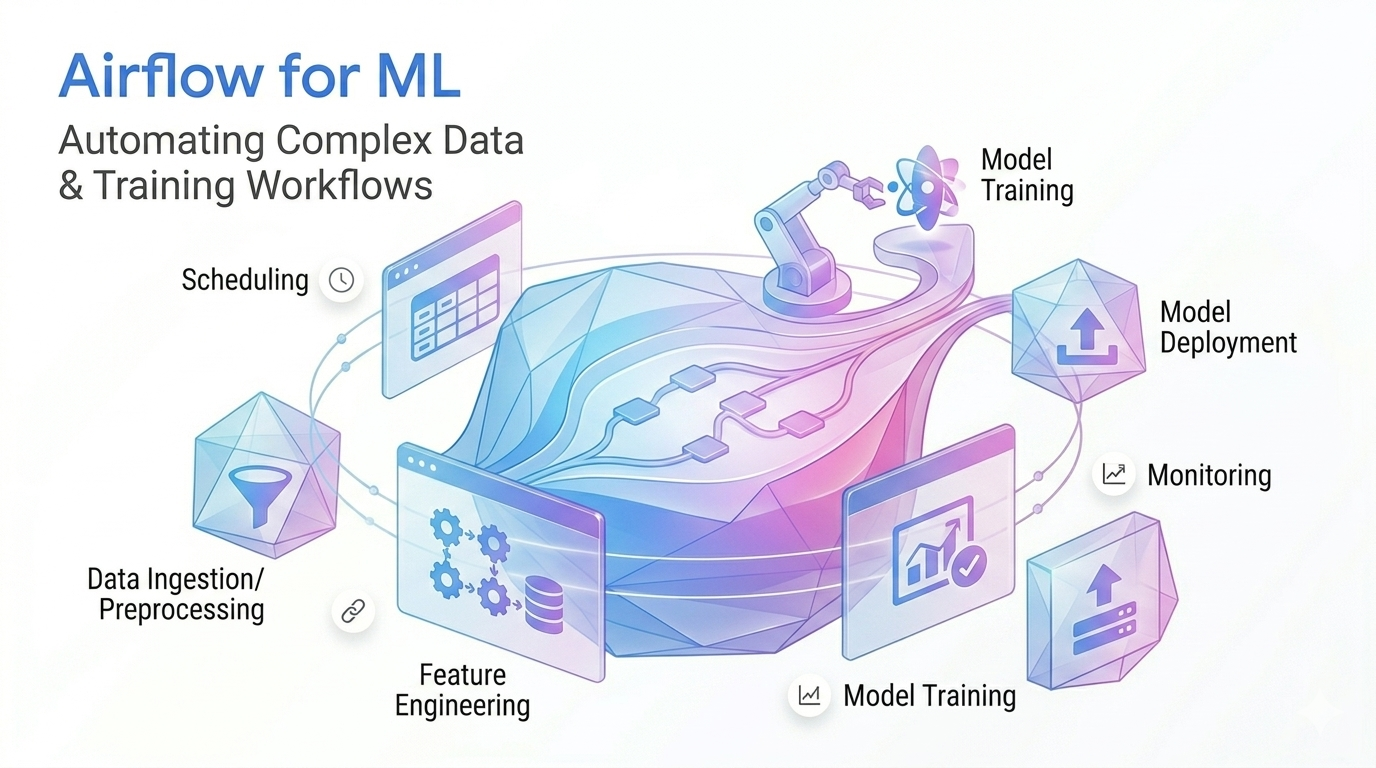
Machine learning systems rely on a complex chain of processes: data ingestion, transformation, feature engineering, training, validation, deployment, and continuous monitoring. In practice, these workflows rarely run in isolation—data pipelines feed models, models trigger evaluations, and performance metrics dictate retraining frequency. As ML adoption scales, organizations need a reliable orchestration layer that can coordinate all these moving parts. This is where Apache Airflow proves invaluable, serving as one of the most trusted orchestrators for managing end-to-end ML pipelines in hybrid and multi-cloud environments.
While modern MLOps tools like Kubeflow Pipelines, SageMaker Pipelines, or Vertex AI Pipelines abstract a lot of ML-specific engineering, Airflow provides unmatched flexibility for complex, cross-functional workflows. Enterprises with heavy data engineering workloads often integrate Airflow deeply into their MLOps architecture because ML pipelines naturally depend on upstream ETL and downstream validation workflows—something Airflow manages better than most specialized ML orchestration tools.
Airflow’s strength lies in its ability to coordinate heterogeneous workloads. ML pipelines depend on data availability, resource scheduling, GPU provisioning, cloud triggers, and model validation logic—all of which can be expressed cleanly using DAGs. Its declarative workflow model ensures that every ML process is reproducible, observable, and trackable. Moreover, Airflow’s integration ecosystem spans nearly every data and cloud service: BigQuery, Snowflake, Redshift, S3, GCS, Azure Blob, EMR, Dataproc, Kubernetes, and more.
To put it simply, ML pipelines don’t live in isolation—and Airflow excels at connecting all the pieces.
Key orchestration strengths Airflow brings into ML workflows include:
These capabilities allow Airflow to orchestrate not just model training, but the entire ML lifecycle.
Most ML failures occur not due to model design, but because the supporting workflows are brittle. With Airflow, teams design ML pipelines that are deterministic, repeatable, and automated across environments. A typical Airflow-based ML pipeline begins with data ingestion and validation, moves through feature engineering and model training, and ends with evaluation, deployment, and monitoring triggers.
This makes Airflow a powerful backbone for production-grade ML pipelines across AWS, Azure, GCP, or on-prem environments.
One of the biggest strengths of Airflow in ML is its deep compatibility with Kubernetes. Most organizations run large training jobs inside containers, and Airflow’s KubernetesPodOperator allows them to spawn isolated pods with precisely defined CPU, GPU, or memory resources. This enables Airflow to orchestrate large-scale training jobs without trying to become a compute engine itself.
Airflow triggers the training job, manages the metadata, waits for completion, and records results—while Kubernetes handles the heavy lifting. This pattern is widely used in GPU-heavy deep learning, NLP model training, and distributed training workloads.
Typical training-stage tasks include:
The separation of orchestration and compute allows Airflow to scale elegantly across hybrid environments.
Once training finishes, Airflow continues orchestrating deployment workflows. Depending on the environment, it can push models into:
Airflow can also enforce governance and safety checks before models move to production, such as verifying accuracy thresholds, ensuring feature schema compatibility, or validating explainability metrics.
Combined with XCom or cloud artifact storage, Airflow ensures complete lineage from dataset → pipeline → model → endpoint.
ML models degrade over time due to drift, evolving data patterns, or system changes. Airflow becomes the scheduling engine for continuous evaluation. It can run daily or hourly pipelines to compute metrics, generate alerts, or restart training workflows.
Monitoring workflows often include:
This enables a closed-loop MLOps system where Airflow orchestrates continuous improvement.
Airflow is incredibly flexible, but ML workflows require intentional architecture. The following best practices ensure reliability, reproducibility, and maintainability across large-scale pipelines:
With these in place, Airflow becomes a central orchestration engine for enterprise ML.
Apache Airflow isn’t an ML-specific tool, but it has become one of the most widely adopted orchestration systems for ML pipelines. Its flexibility, deep integrations across data and cloud ecosystems, and ability to manage multi-stage workflows make it ideal for production-grade MLOps. For organizations looking to streamline data ingestion, automate training workflows, enforce governance, and deploy models reliably across clouds, Airflow remains a foundational piece of infrastructure.